

An efficient exploration into the realm of computer vision
A Primer to Computer Vision


Overview
Computer vision, much like the way human vision operates, involves the capacity of a computer system to extract significance and understanding from a variety of visual or electrical inputs. Just as humans interpret and comprehend the world through visual cues, computers equipped with computer vision technologies can process and analyze images, videos, and other visual data to derive meaningful information. This process involves the utilization of advanced algorithms and techniques to identify patterns, objects, relationships, and contextual details within the visual input, thereby allowing the computer to effectively "see" and interpret its surroundings in a manner analogous to human perception.

Introduction
Computer vision is a field of artificial intelligence and computer science that focuses on enabling computers to interpret, process, and understand visual information from the world, similar to how humans perceive and understand the visual world. It encompasses a wide range of techniques, algorithms, and technologies to extract meaningful information from visual data.

Key Concepts and Components
Computer vision encompasses the following key concepts;
Image Formation: The process starts with understanding how images are formed. Images are made up of pixels, each with its own color or intensity value. Cameras and other imaging devices capture light and convert it into pixel values, forming digital images.
Preprocessing: Before analysis, images often undergo preprocessing steps to enhance the quality of the data. This might involve noise reduction, contrast enhancement, and image resizing.
Feature Extraction: Feature extraction involves identifying key elements or patterns in an image that are important for analysis. These features could be edges, corners, textures, or other distinctive attributes.
Image Recognition: This involves classifying or categorizing objects or scenes within images. Convolutional Neural Networks (CNNs) have revolutionized this area by automatically learning relevant features from data.
Object Detection: Object detection goes a step beyond recognition by not only identifying objects but also locating them within an image. This is commonly used in applications like self-driving cars and surveillance systems.
Image Segmentation: Segmentation involves dividing an image into different segments or regions based on certain criteria. It's used to precisely locate object boundaries within an image.
Image Generation: This area focuses on generating new images from scratch, often using generative adversarial networks (GANs) or variational autoencoders (VAEs).
3D Computer Vision: While 2D computer vision deals with images, 3D computer vision adds depth information, allowing for the reconstruction of three-dimensional scenes from images or videos.
Motion Analysis: Motion analysis is concerned with tracking objects or understanding the motion of objects over time. Optical flow and tracking algorithms play a role in this domain.
Depth Estimation: This involves estimating the depth information of a scene from 2D images. It's crucial for applications like augmented reality and robotics.
Semantic Segmentation: Semantic segmentation aims to classify each pixel in an image into a predefined class, providing a detailed understanding of the scene.
Transfer Learning: Due to the computational complexity of training deep neural networks, transfer learning is often used. Pretrained models are fine-tuned for specific tasks using smaller datasets.
Data Augmentation: Increasing the diversity of training data by applying transformations like rotations, flips, and brightness adjustments, enhancing the model's generalization.

Object recognition architectures: Various architectures like AlexNet, VGG, ResNet, and EfficientNet have pushed the boundaries of object recognition performance in benchmarks like ImageNet.
Applications

Autonomous Vehicles: Enabling vehicles to perceive their environment and make decisions based on the analysis of visual data.
Medical Imaging: Assisting doctors in diagnosing diseases through techniques like image segmentation, classification, and anomaly detection.
Surveillance and Security: Monitoring and analyzing video feeds for detecting anomalies, identifying individuals, and tracking objects.
Augmented Reality (AR) and Virtual Reality (VR): Integrating digital information with the user's view of the real world or immersing them in entirely virtual environments.
Industrial Automation: Inspecting products for defects, guiding robots, and optimizing manufacturing processes.
Retail: Enhancing customer experience through applications like facial recognition for payments and inventory management.
Entertainment: Creating special effects, animating characters, and generating realistic graphics in movies and video games.
Agriculture: Monitoring crop health, estimating yields, and automating tasks like fruit picking.
Environmental Monitoring: Analyzing satellite imagery to track changes in land use, deforestation, and natural disasters.
Challenges
Variability in Data: Images can have diverse lighting conditions, viewpoints, backgrounds, and occlusions.
Large Datasets: Training deep learning models requires vast amounts of labeled data, which might not always be readily available.
Overfitting: Models can become too specialized to the training data and perform poorly on new, unseen data.
Computational Complexity: Deep learning models are computationally intensive and might require powerful hardware for training and inference.
Interpretable AI: Understanding how deep learning models make decisions is still an ongoing challenge.
Ethical Concerns: Issues like bias in data, privacy concerns, and potential misuse of technology need careful consideration
Conclusion
In conclusion, computer vision's rapid advancement and its applicability across diverse industries make it an exciting and dynamic field. Staying informed about the latest developments is essential for professionals and researchers to harness their potential and drive innovation forward.
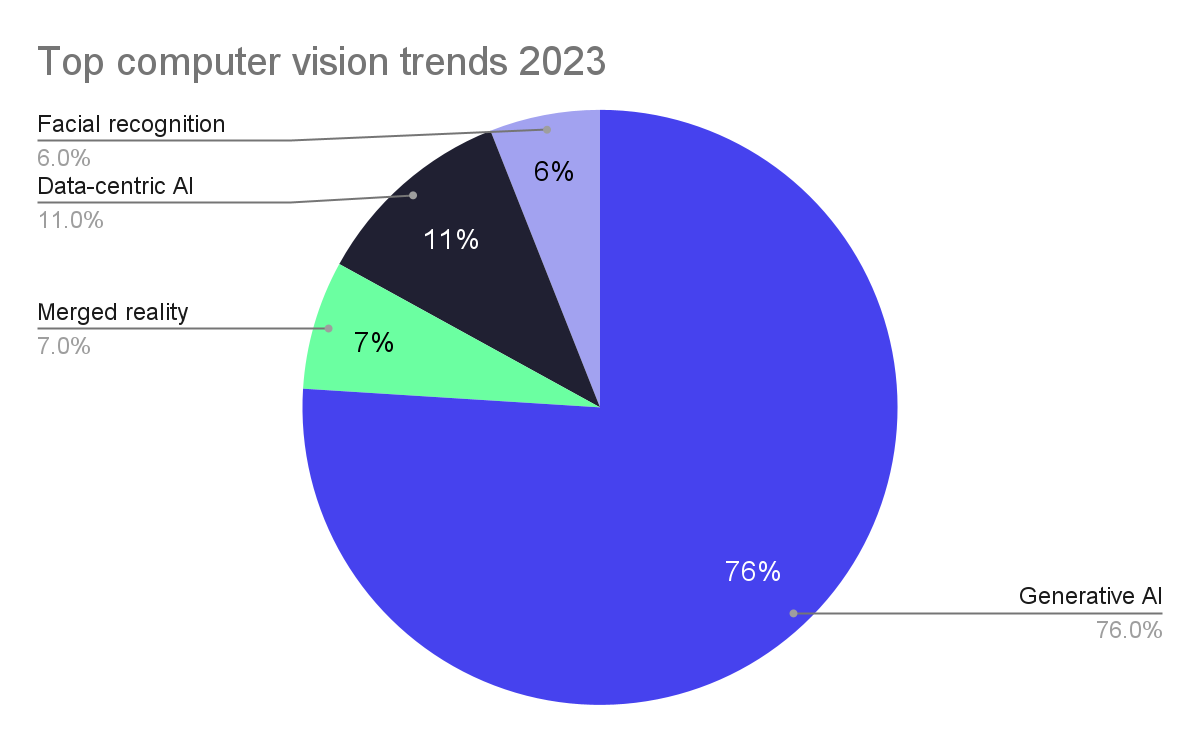
Relevant Resources
Online Courses: Platforms like Coursera, edX, and Udacity offer specialized computer vision courses.
Books: "Computer Vision: Algorithms and Applications" by Richard Szeliski and "Deep Learning for Computer Vision" by Rajalingappaa Shanmugamani.
Open Source Libraries: OpenCV and TensorFlow provide tools and resources for various computer vision tasks.
Research Papers: Explore arXiv and other academic platforms for the latest advancements in computer vision.
Online Communities: Participate in forums like Stack Overflow, Reddit's r/computervision, and Kaggle for discussions and learning.
Practical Projects: Implement projects involving object detection, image classification, and segmentation to gain hands-on experience.
I appreciate your thoughtful review of this technical document. I hope you found it engaging. If you're interested in delving deeper into the subjects of computer vision and artificial intelligence, please feel free to reach out. I'd be more than happy to provide you with further insights and resources on these intriguing topics.